AI 到底有多聰明?——一份讓 AI 研究者也困惑的成績單
當前位置:點晴教程→知識管理交流
→『 技術文檔交流 』
上一章我們拆開了 AI 的黑箱,得到了一個核心結論:AI 是超級模式匹配器。 但這個結論到底有多大的解釋力?先做一個測試。 看完下面這組數據,請你給 GPT-4 一個評價——"聰明"還是"不聰明":
給一些參照系。SAT 滿分 1600 分,美國高中生平均約 1050 分,GPT-4 考了 1410——全國前 5%。GRE 語文 169 分,超過了 99% 的考生——而這些考生本身已經是大學畢業生。 如果這是一個人類考生,你會說:天才。 現在翻面。 同一個 GPT-4:
一個 SAT 1410 分的"天才",連 9.11 和 9.8 的大小都搞錯?
好,這是 2023 年的成績單。你可能會想:三年過去了,新模型總該解決這些問題了吧? 再看一份。 2025-2026 年,最新 AI 模型的成績單:
數據來源:OpenAI、Artificial Analysis、Vellum 數學競賽滿分,研究生級科學題超越專家,真實編程任務八成搞定。三年進步之大,令人咂舌。 現在翻面。 同一批 2025-2026 年的模型:
三年后,矛盾不但沒消失,反而升級了——連研究 AI 的人自己也在為同一個問題爭論不休:這些模型到底是真的在"推理",還是學會了更高級的"模式匹配"? 如果你覺得這個問題比三年前更難回答,恭喜——你看到了 2026 年 AI 領域最核心的困惑。 你用錯了尺子這個問題之所以難回答,不是因為你對 AI 了解不夠,而是因為「聰明還是不聰明」這個問題本身就是錯的。 為什么你會覺得這組數據矛盾? 因為你在不自覺地做一個假設:「聰明」是一個統一的整體。 對人類來說,這個假設基本成立。一個能通過律師考試的人,不會連 9.11 和 9.8 都比不清楚。一個 GRE 語文 99 百分位的人,小學數學不會錯。人類的各種認知能力之間有很強的關聯性——語言能力強的人,邏輯能力通常也不差。心理學上叫這個"g 因子"——一種貫穿所有認知任務的一般智力因素。 但 AI 不是這樣。 AI 的"聰明"是碎片化的。 它在不同任務上的能力可以相差幾個數量級——律師考試前 10%,同時連小數比大小都會搞錯。這兩件事在 AI 身上同時成立,沒有任何矛盾。 為什么?因為 AI 的每一項能力,都是從那個特定領域的訓練數據中學來的。律師考試的能力來自海量法律文本中的問答模式。小數比較的"能力"來自——這個我們下面說。 用「聰明不聰明」來評價 AI,就像用「高不高」來描述一條河。 一條河有的地方深不見底,有的地方你能蹚過去。說它"深"或"淺"都不對——你得說"在哪個位置有多深"。 AI 也一樣。你不能問"AI 聰明嗎"。你得問"AI 在這個具體任務上有多強"。 2026 年的數據讓這個特征更加鮮明——像一個數學競賽滿分、但換個數字就做錯的學生。不是偶爾失誤,而是結構性地:某些維度強到超越人類專家,某些維度弱到讓人匪夷所思。
用第一章的工具拆解這張成績單第一章我們知道了 AI 是模式匹配器。但"模式匹配器"這三個字還不夠用——它沒有告訴我們為什么同一個模式匹配器在不同任務上差距如此巨大。這一篇要解決的就是這個問題。 "碎片化"這三個字說起來容易,但為什么會碎片化? 這就需要用到第一章學過的知識了。讓我拿成績單上的三個數據做手術,你會看到每一個數字背后的原因都不同——而且全部可以用第一章的原理解釋。 手術一:為什么能通過律師考試?答案是:考試題的模式,在訓練數據中大量存在。 GPT-4 的訓練數據包括了互聯網上海量的法律文本——教科書、判例摘要、考試輔導材料、法律論壇。這些文本中反復出現這樣的模式:
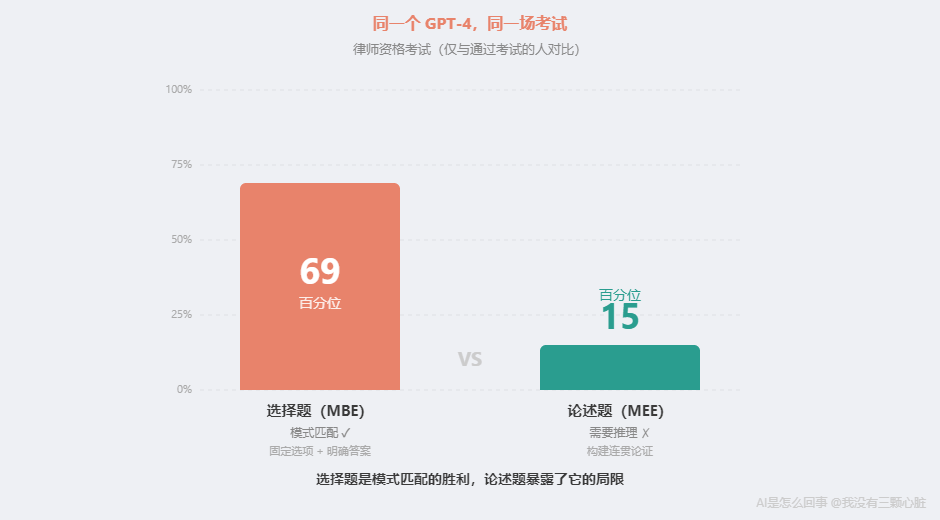
當 GPT-4 在考試中看到類似問題時,它做的和訓練時一模一樣:根據題目中的文字模式,預測最可能的答案。 這不是"懂法律",是"見過太多法律題了"。 打個比方:讓一個人做 10 萬道律師模擬題,每道都告訴他正確答案,但從來不講為什么。10 萬道之后,他大概率也能通過考試——不是因為"理解"了法律,而是見過了足夠多的模式。 但有個數據很能說明問題。MIT 博士生 Eric Martinez 在 2024 年發表的重新評估研究中發現:GPT-4 在選擇題上大約排在全體考生的第 69 百分位,但如果只看論述題、只和通過考試的考生比,它只排在約第 15 百分位——85% 的通過考試的人比它寫得好。 為什么選擇題強、論述題弱?因為選擇題是典型的模式匹配——有固定選項、有明確答案、訓練數據中有大量類似問答對。論述題需要構建連貫的法律論證——理解概念之間的因果關系,不能只識別模式。 選擇題是模式匹配的勝利。論述題暴露了模式匹配的局限。
到了 2025 年,這個發現有了一個更精確的驗證。Apple 在 ICLR 2025 上發表了一項名為 GSM-Symbolic 的研究,結果令人震驚:
Apple 的結論措辭非常強硬:
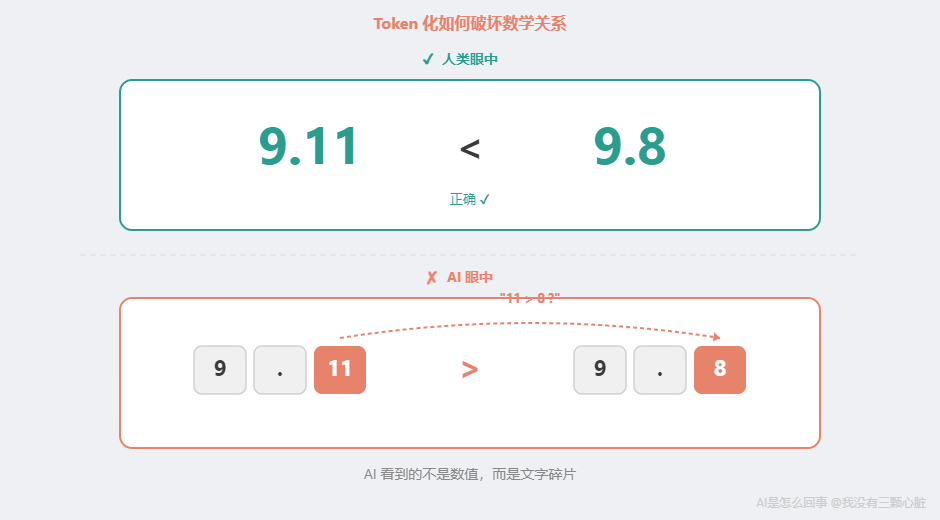
不過,這個結論也招致了爭議。研究者 Alex Lawsen 指出,部分發現可能源于實驗設計的限制(比如輸出長度被截斷)。后續論文 "Rethinking the Illusion of Thinking" 得出了更細致的結論:并非全部可以歸結為實驗缺陷,AI 推理確實存在認知局限——但局限的程度還在爭論中。 換句話說——連研究者自己也沒有達成共識。 這是 2026 年 AI 領域最大的未解之謎之一。 手術二:為什么算不對 9.11 > 9.8?這個錯誤看起來離譜,但用第一章的知識可以精確解釋。這里面有兩層原因。 第一層:它根本不是在"計算"。 當你讓 ChatGPT 比較 9.11 和 9.8 的大小時,它沒有一個"數學模塊"在工作。它做的仍然是那一件事:預測下一個最可能的詞。 它看到"9.11 和 9.8 哪個大"這段文字,然后在訓練數據中尋找類似模式。簡單算術("2+3=5")在訓練數據中出現了無數次,模式已經被記住。但"比較兩個小數"這種任務,在訓練數據中的覆蓋遠不如考試題那么充分。 第二層:Token 化把數字的數學關系破壞了。 還記得第 2 篇講的 Token 化嗎?AI 處理文字的第一步是把文字切成小塊。 Token 化可能會讓數字的數學關系被破壞——數字被拆成單獨的字符或片段后,AI 看到的不再是一個完整的數值,而是幾個獨立的文本碎片。比如"9.11"和"9.8"被拆開后,AI 可能更關注碎片之間的文字模式("11 大于 8"),而非小數本身的數學含義——于是它預測"9.11 更大"。 數字之間的數學關系(大小、相鄰、倍數)在 Token 化過程中被破壞了。 在 AI 眼中,9.11 和 9.8 不是兩個可以比較的數值——它們是幾個沒有數學含義的文字碎片。 到了 2026 年,這類基礎算術錯誤已經大幅減少,但沒有完全消失。根據 2026 年 2 月 ORCA 基準測試,即使最好的模型在 500 道實用數學題上也只能拿到 C 級成績。在所有錯誤中,計算錯誤占了 39.8%——不是不會推理,而是算不對。 但有一個關鍵發現:當 AI 可以調用外部計算器(比如 Python)時,準確率從約 70% 直接跳至接近 100%。 這說明問題不在"理解題意",而在"執行計算"——AI 能讀懂問題、列出步驟,但在具體算數的時候會出錯。就像一個數學老師能完美地講解解題思路,但自己心算乘法時會出差錯。 問題不在"推理",而在"執行"。
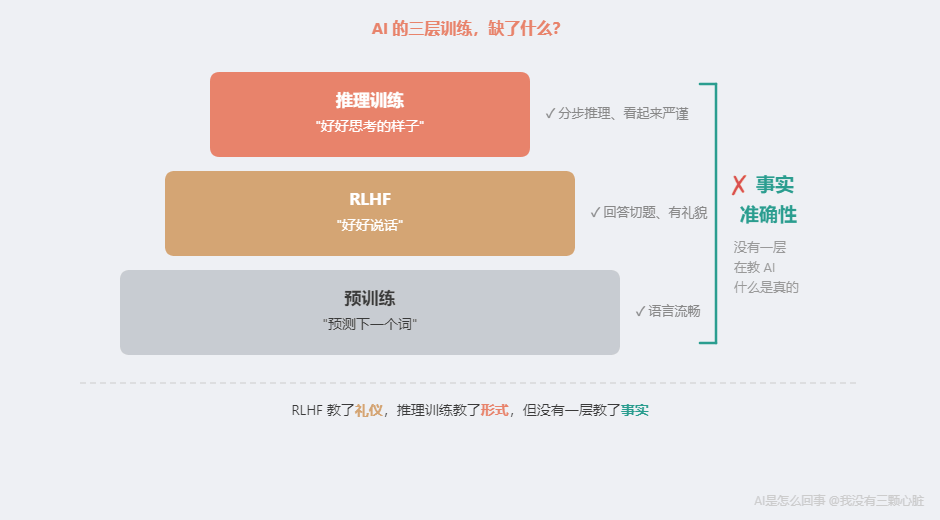
現在回頭看:律師考試能過,因為法律問答模式在訓練數據中覆蓋充分。小數比較出錯,因為數學關系在 Token 化中被破壞了。數學計算不準,因為 Token 預測不是計算器。 每一個能力都來自完全不同的"源頭",彼此之間毫無關聯。這就是"碎片化"的含義。 手術三:為什么它說話像一個靠譜的人?還有一個謎團沒解開。 如果 ChatGPT 只是在"猜下一個詞",為什么它大多數時候回答問題看起來那么靠譜——有條理、切題、像一個真正懂行的人在說話? 答案是:ChatGPT 不只是一個語言模型。它還經過了一種特殊訓練——RLHF(Reinforcement Learning from Human Feedback,用人類反饋進行強化學習)。 在 ChatGPT 之前,OpenAI 發布了 GPT-3(2020 年)。GPT-3 有 1750 億參數,預測下一個詞的能力已經很強。但直接用起來體驗很糟糕——你問"請用簡單的語言解釋黑洞",它可能寫兩千字的天文學論文。你說"今天心情不好",它給你一篇抑郁癥流行病學綜述。它不是不聽你的話——它根本不知道什么叫"聽話"。 RLHF 解決了這個問題。它的核心邏輯用一句話就能說清楚:
結果呢?OpenAI 做了一個直接對比。原始 GPT-3 有 1750 億參數,經過 RLHF 訓練的 InstructGPT 最小版本只有 13 億參數——小了 100 多倍。但標注員在 85% 的情況下更偏好 InstructGPT。 一個小了 100 多倍的模型,因為"學了禮儀",比"沒學禮儀"的大模型更受歡迎。 RLHF 沒有讓 AI 變得更"聰明"。它的底層仍然是"預測下一個詞"。RLHF 做的是讓 AI 在預測時,更傾向于預測出"人類覺得有用、安全、切題"的那個詞。而且,OpenAI 在論文中坦承:經過 RLHF 訓練后,模型在某些基準測試上出現了所謂的"對齊稅"(alignment tax)——為了讓回答更符合人類偏好,部分客觀指標反而有所下降。
那 2025-2026 年的"推理模型"呢? 2024 年末,OpenAI 推出了 o1 模型,開創了一種新范式:讓模型在回答之前先"思考"——生成一段內部推理鏈,一步步分析問題再給出答案。后續的 o3、o4-mini 在數學競賽和編程任務上表現驚人。 但這里出現了一個 詭異的悖論。 這些專門為"深度推理"設計的模型,在事實準確性上反而更差:
原因分析:為了"好好推理"而優化的模型,傾向于用看似合理的推測來填補知識空白——推理鏈越長,編造看起來越"有道理"。 RLHF 教會了 AI "好好說話"。推理訓練教會了 AI "好好思考的樣子"。但兩者都沒有教會 AI 什么是"事實"。
三把手術刀指向同一個結論現在讓我們把三次手術的結果放在一起看。
三個表現,三個原因,彼此之間完全獨立。 律師考試的能力不會幫助它比較小數。RLHF 的"禮儀訓練"不會讓它學會數學。每一項能力都是獨立習得的,取決于那個特定維度上的訓練數據和任務結構。 這就是為什么"AI 有多聰明"是一個錯誤的問題。 它暗示存在一個統一的"聰明度"可以衡量。但 AI 不是這樣——它是一個極其不均勻的能力拼圖,每一塊拼圖的大小取決于完全不同的因素。 正確的問題是:「AI 在這個具體任務上有多強?為什么?」 一把新尺子——連尺子本身也在被質疑如果你接受了這個認知轉換,你會發現看 AI 新聞的方式會發生質變。 以前:
現在:
你不需要對每條 AI 新聞感到驚喜或恐慌。你只需要問一個問題:這個任務的性質是什么?
但 2025-2026 年又拋出了一個新問題:連我們測量 AI 的尺子本身,也在被質疑。 傳統基準測試正在被"打穿"。MMLU(57 個學科的多任務語言理解測試)前沿模型已普遍超過 88%,幾乎無法區分誰更強。更難的 MMLU-Pro 在 2025 年 11 月就被 Gemini 3 Pro 以 90.1% 飽和。研究者不得不反復造更難的考試來測 AI——GPQA Diamond、HLE(Humanity's Last Exam)、ARC-AGI-2……一個接一個。 而新的"最難考試"也暴露了新問題。以發表在 Nature 上的 HLE(Humanity's Last Exam)為例——2500 道跨 100 多個學科的超難題,目前最好的模型也只答對 44.7%。但研究者發現,模型的校準誤差高達 34% 到 89%——也就是說,AI 表示"我有 80% 把握"的時候,實際正確率可能只有 40%。它不是不知道自己不知道,而是系統性地高估自己。 這意味著什么? 不僅 AI 的能力是碎片化的,連我們衡量這些能力的工具也在不斷失效。 后面幾篇我們會把這把尺子磨得更鋒利——從 AI 繪畫到 AlphaGo 到自動駕駛,我們會在更多領域測試這把刀,最終鍛造成一套可以隨身攜帶的判斷工具。 個人錨點說實話,"AI 聰明嗎"這個問題,我自己糾結了很久。 有一次我讓 ChatGPT 幫我把一篇英文技術文章翻譯成中文。它翻得非常好——術語準確,句式流暢,比我自己啃原文快了十倍。然后我順手讓它算一道四位數乘法:1247 × 3829。 它算錯了。我拿計算器驗一下就知道。 同一個對話窗口。上一秒還在完美處理復雜的英文長句,下一秒連乘法都算不對。 后來我意識到,問題不在 AI,在我。我一直在用一把"人類智能"的尺子去量一個完全不同的東西。 翻譯是模式匹配——訓練數據中有海量雙語對照,AI 的主場。但算乘法不是模式匹配——正文里分析過,AI 不是在"計算",而是在"猜下一個最可能的數字"。 兩個任務,兩種性質,兩種表現。不是 AI 時聰明時愚蠢,是不同任務落在了它的能力拼圖上不同的位置。 2026 年,這種困惑有了升級版。看到 GPT-5.2 數學競賽滿分的新聞,我的第一反應是"AI 終于真的會推理了?"。然后看到 Apple 的 GSM-Symbolic 論文——換個數字就做錯——又開始懷疑。再看到 ARC-AGI-2 上人類依然領先——更困惑了。 但現在我不再糾結了。因為我知道:這不是一個需要選邊站的問題。 AI 在某些維度上超越了人類專家,在另一些維度上不如小學生。這兩件事同時成立,不需要調和。 理解這一點之后,我再也沒有在"AI 好厲害"和"AI 好蠢"之間搖擺過。 一句話回顧
轉自https://www.cnblogs.com/wmyskxz/p/19655155 該文章在 2026/3/2 8:34:12 編輯過 |
關鍵字查詢
相關文章
正在查詢... 



|


 400 186 1886
400 186 1886